.png)

Why You Shouldn’t Rely on ChatGPT for Election Advice
- social
- Feb 20, 2025
- 3 min read
Updated: Apr 9, 2025
By Sebastian Krauß • 20/02/2025
With the German federal elections (Bundestagswahl 2025) approaching, many voters are unsure which party best aligns with their political views. Tools like Wahl-O-Mat help users compare their positions with those of different political parties. At the same time, the rise of AI-powered chatbots, such as ChatGPT, has led to more people seeking political insights from generative AI. If this trend continues, AI-based assistants could play an increasingly significant role in shaping voter opinions. However, their truthfulness and neutrality remain critical concerns in democratic elections. How well do large language models (LLMs) align with party positions? In this post, we evaluate the responses of AI models to Wahl-O-Mat questions, assessing their alignment with major German political parties.
What Is the Wahl-O-Mat?
The Wahl-O-Mat is an interactive tool provided by the German Federal Agency for Civic Education (bpb). It presents users with 38 political statements, allowing them to indicate their agreement, disagreement, or neutrality. Based on these responses, the tool calculates how closely the user aligns with various political parties.
How We Tested LLMs
To evaluate the accuracy of LLMs in political alignment, we designed a structured experiment:
Selecting Political Parties: We focused on the seven largest German political parties: CDU/ CSU, SPD, AfD, Bündnis 90/ Die Grünen, Die Linke, FDP, and BSW.
Creating a Test Set: We compiled a dataset of 38 Wahl-O-Mat statements, using the official party positions as ground truth.
Example:
• “Germany should continue to support Ukraine militarily.” (Wahl-O-Mat)
• “According to the CDU/ CSU, should Germany continue to support Ukraine militarily?” (Test Set)
Generating AI Responses: Each test model was prompted with the Wahl-O-Mat questions and instructed to respond as if it were a specific political party. The responses were restricted to “Yes,” “No,” or “Neutral.”
Measuring Accuracy: We compared AI-generated responses with the ground truth and calculated accuracy scores.
How accurate are the LLMs?
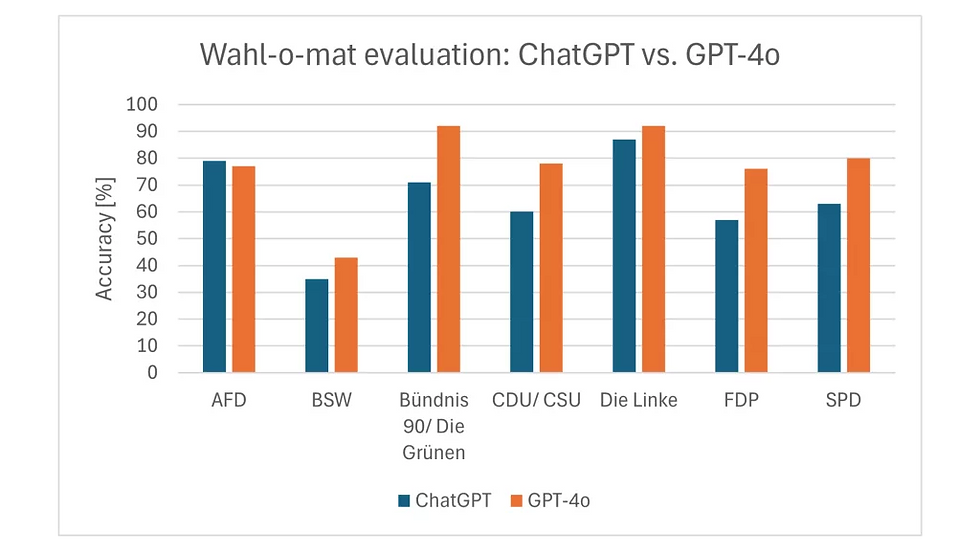
Our results show that all tested models achieved accuracy rates between 60% and 80%, indicating that LLMs struggle to provide reliable political alignment recommendations. The best-performing model was GPT-4o (version 2024-11-20), while ChatGPT, based on a GPT-4o model, had a lower accuracy of just 65%.

A deeper analysis of GPT-4o and ChatGPT revealed two key findings:
Accuracy varies by party: The responses for parties like AfD and Die Linke were more accurate than for BSW, which had an accuracy of less than 50%. This is alarming as factual correctness of LLMs differs by party which may cultivate in biases against certain parties.
GPT-4o outperforms ChatGPT: GPT-4o demonstrated higher accuracy in aligning with party positions across nearly all parties, with the exception of AfD. However, since many users still rely on models like ChatGPT instead of state-of-the-art systems, most voters may receive less accurate or less reliable political insights. This discrepancy raises concerns about the potential impact of AI-generated information on democratic elections.
Why Do LLMs Perform Poorly?
Several factors contribute to the suboptimal performance of LLMs in this context:
Limited Training Data: AI models are trained on historical data, meaning they lack access to the most recent political party programs, many of which were published only in the past few months.
Data Bias and Misinformation: LLMs may incorporate misinformation from unreliable online sources. They also tend to hallucinate, especially if the answer is not clear.
Party-Specific Challenges: The accuracy disparity between parties likely results from differences in data availability. BSW, founded in 2024, has limited historical data, making it difficult for models to predict its positions accurately. In contrast, AfD and Die Linke have maintained consistent ideological stances for many years, making their positions easier to approximate.
Internet Access Doesn’t Improve Results: Unlike GPT-4o, ChatGPT has access to the internet, which could, in theory, improve accuracy. However, our findings indicate that ChatGPT does not perform better. Given that its answers vary when asked the same question multiple times, its reliability is questionable when it comes to alignment with different political views.
Conclusion
Our experiment demonstrates that while LLMs can describe and explain political positions to a certain point, they are not reliable sources of information for elections. They should not replace tools like the Wahl-O-Mat or other authoritative resources. As AI becomes more integrated into decision-making processes, it is crucial to evaluate its trustworthiness. At Validaitor, we develop new methods and strategies to assess AI safety and reliability across various use cases. If you want to learn more about AI testing, you can look at this article where we evaluate fairness in popular LLM models, this article where we take a deeper look into hallucinations in generative AI or this article about prompt injection attacks.
References
Wahl-o-mat Bundestagswahl 2025, https://www.wahl-o-mat.de/bundestagswahl2025/app/main_app.html


